Tutorial: PostgreSQL Assistant
4 min readOverview
In a few steps we will show you how to create a RAG application using Needle.
- Step 1: You will create a collection in Needle and add the PostgreSQL documentation to it.
- Step 2: We will show you how you track the status of the collection.
- Step 3: How to perform a search in the collection.
- Bonus step: Compose an answer from the search results.
Intro
We love working with PostgreSQL, we use it for our own projects and we know that many of you do too. It packs in so many features that it can be hard to keep track of them all - for our human brains!
That's why it makes sense to create an assistant specifically tailored-towards PostgreSQL. Without having to be very creative, we will call it the PostgreSQL Assistant.
Why is that better than asking your questions on ChatGPT, Stack Overflow or Reddit? We will give short answers:
- ChatGPT: It can hallucinate and give you wrong answers. Or the anwer applies to an older version of PostgresSQL.
- Reddit: You have to wait for an answer, and you might not get one - or it can be wrong.
- Stack Overflow: Same as above, furthermore the community is shrinking and the quality of answers is decreasing.
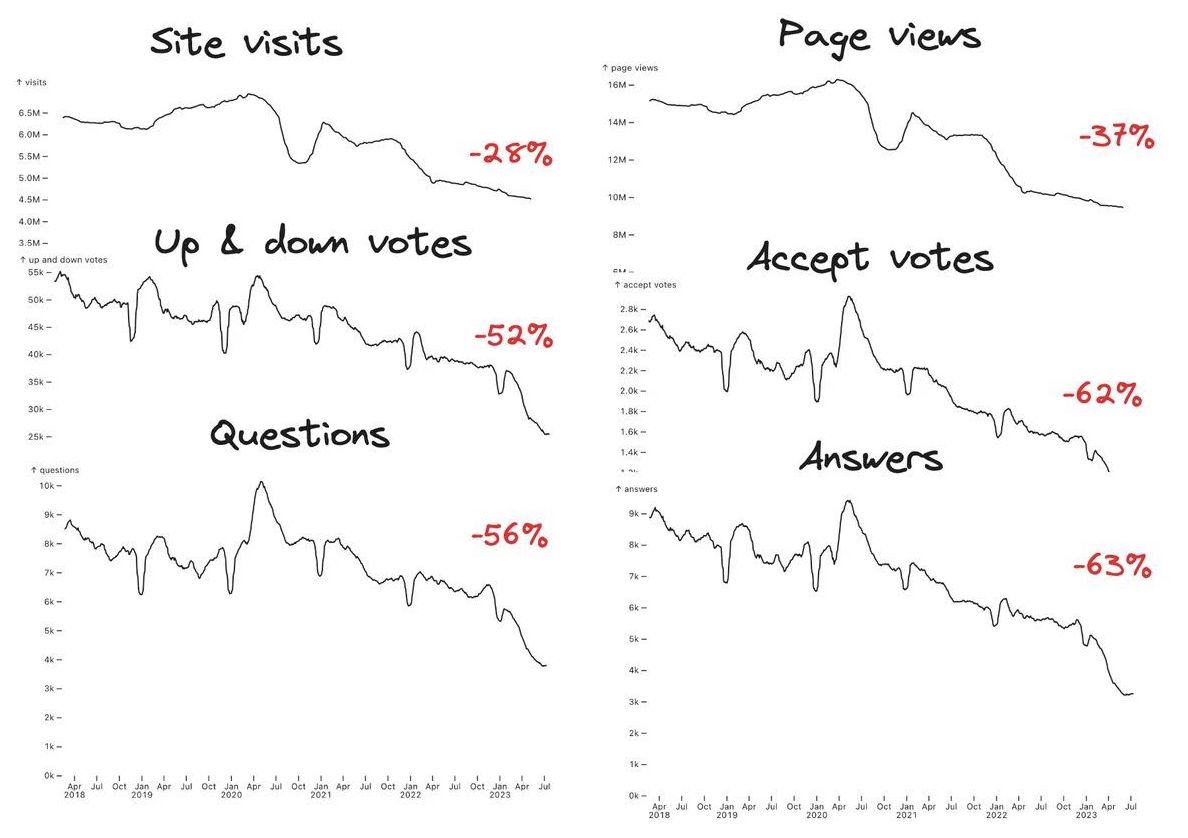
Key metrics for Stack Overflow are in decline.
PostgreSQL Assistant is like having a PostgreSQL expert at your fingertips because all answers come from the official PostgreSQL documentation. Without further ado, let's get down to it.
Step 1: Create a collection
Login to Needle and create an empty collection named PostgreSQL Assistant. Click on the collection to open it and go to Files tab. Click on the Add Files button use the URL adder and enter the value: https://www.postgresql.org/files/documentation/pdf/16/postgresql-16-A4.pdf
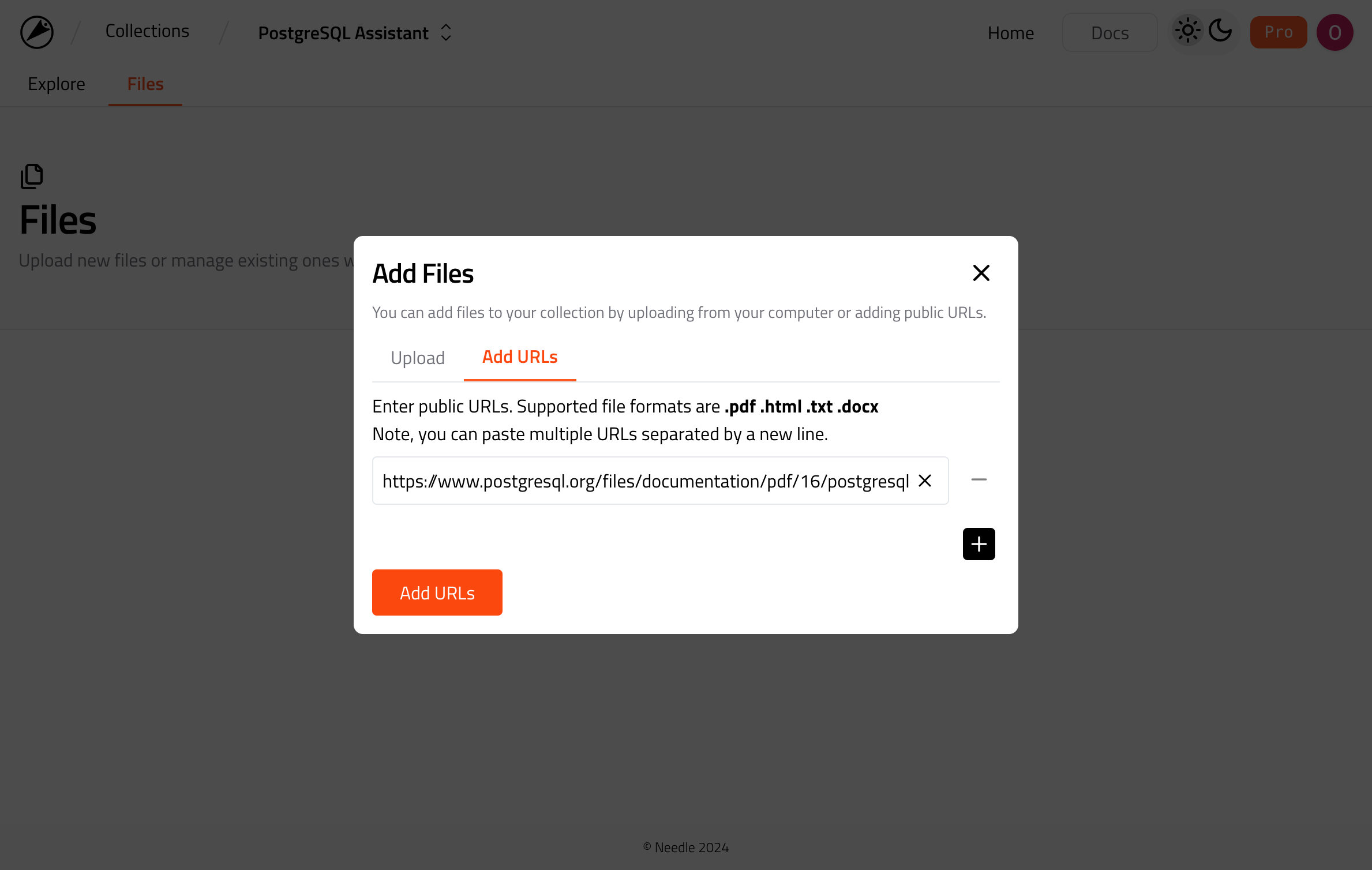
Adding file to Needle collection via web interface.
You can, of course, do this via the Needle API as well. That can come handy in case you want to integrate Needle into your automations. See the code sample below:
from needle.v1 import NeedleClient
from needle.v1.models import FileToAdd
ndl = NeedleClient()
collection = ndl.collections.create(name="PostgreSQL Assistant")
ndl.collections.files.add(
collection_id=collection.id,
files=[
FileToAdd(
url="https://www.postgresql.org/files/documentation/pdf/16/postgresql-16-A4.pdf",
name="PostgreSQL 16 Documentation",
)
],
)
Step 2: Track the collection status
Adding one file sounds minimal right, is it really RAG if it's just one file? 😅
But the PostgreSQL documentation is huge! It's over 3000 pages long and contains more than 7.2M characters. So creating a context from this documentation in ChatGPT is in the end a big deal... literally, in terms of cost.
After the upload give Needle some time, so it will be indexed and ready to be searched. You can track the status of the file in the Files tab.
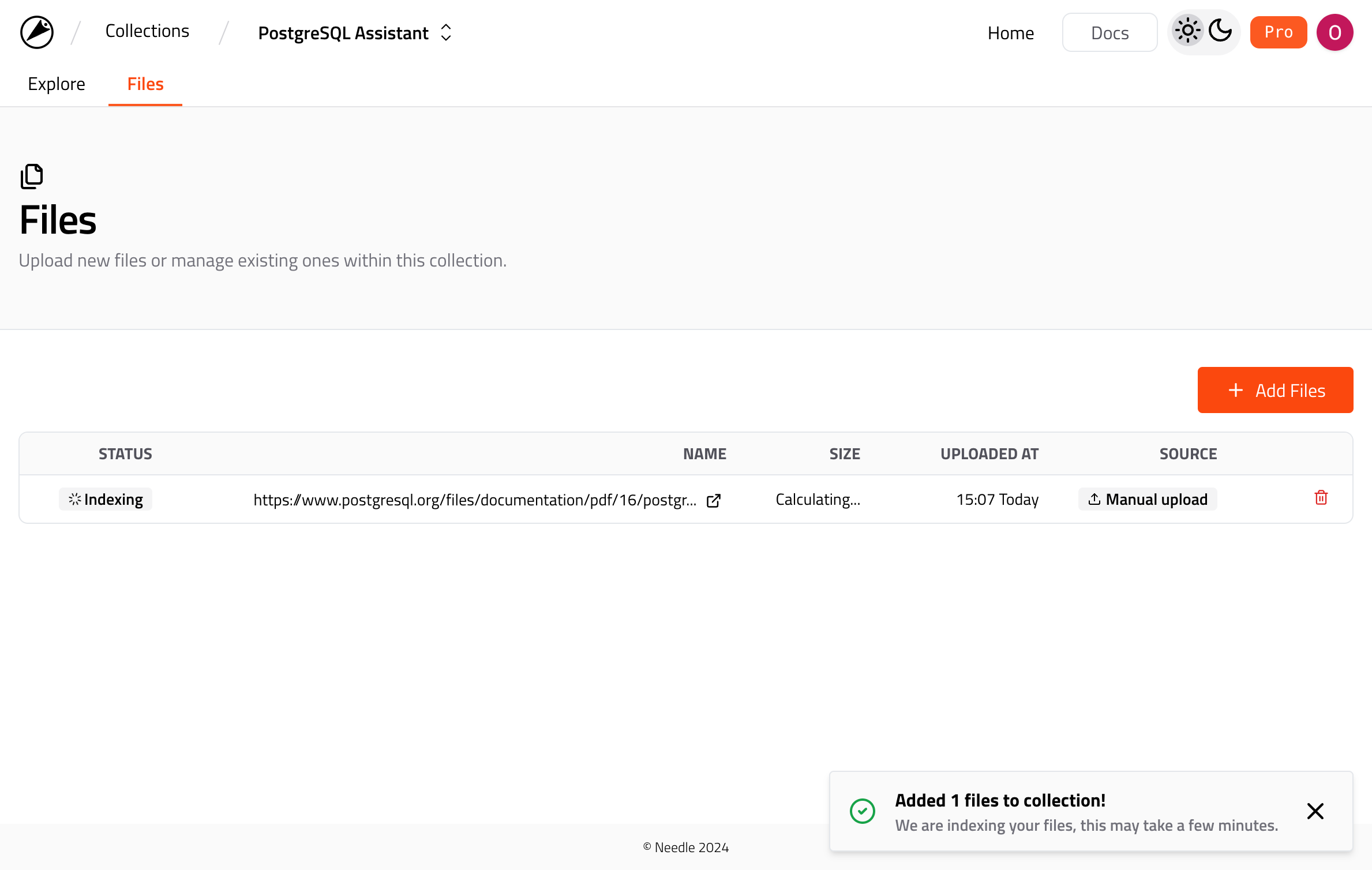
PostgreSQL documentation being indexed.
Or alternatively, you can again use the Needle API to track the status of the files in a collection:
files = ndl.collections.files.list(collection_id)
is_ready = all(f.status == "indexed" for f in files)
Step 3: Search your collection
Generally speaking, you don't have to wait for the indexing to finish. If there are already other indexed files in your collection, you can perform search in that collection. It's just that, when a file indexing is complete, your search results will include chunks from that file as well. Since in this particular case there's only one file, it makes sense to wait until it's ready.
You can search your collection in the Explore tab. See an example below:
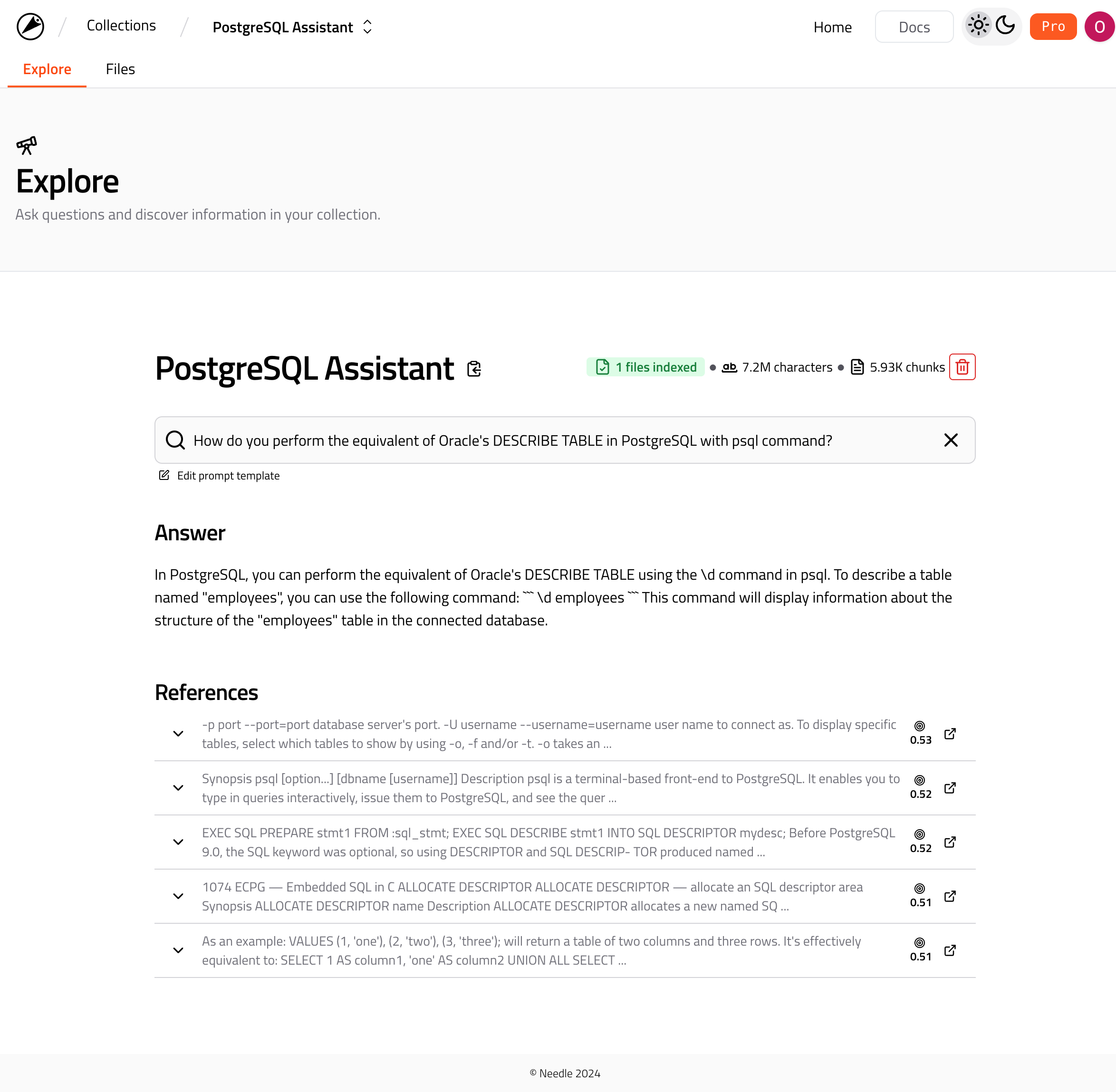
Searching your collection in Needle.
Notice that the search results provide 1) Answer and 2) References as the basis of the answer. Here behind the scenes, we are building an augmented prompt by combining your question and references, i.e. chunks, that are retrieved from the collection.
Like as always, you can perform the search via the Needle API as well:
prompt = "How do you perform the equivalent of Oracle's DESCRIBE TABLE in PostgreSQL with psql command?"
results = ndl.collections.search(
collection_id=collection.id,
text=prompt,
)
for r in results:
print(r.content)
We would like to point out that Needle is not an LLM, nor it packages one within it. Although we display an LLM composed answer in the web interface that is only for demo purposes. In many cases, you would like to customize the final steps of your RAG pipeline.
Bonus: Build a custom prompt
Since we are talking about customizing the final steps of your RAG pipeline, let's see how you can build a custom prompt. In this example we are using OpenAI's models, however it's up to you to choose the model that fits your needs.
openai = OpenAI()
# set the context with results from Needle
system_messages = [{"role": "system", "content": r.content} for r in results]
user_message = {
"role": "system",
"content": f"""
Only answer the question based on the provided results data.
If there is no data in the provided data for the question, do not generate an answer.
This is the question: {prompt}
""",
}
answer = openai.chat.completions.create(
model="gpt-4o-mini",
messages=[
*system_messages,
user_message,
],
)
print(answer.choices[0].message.content)
Conclusion
In this tutorial, we have shown you how to create a collection in Needle, track the status of the files in the collection, and search the collection. In several lines of code you can bring magic of RAG to the data of your choice and create specialized agents in minutes.
We used PostgreSQL documentation as an example, but you can use any other data source that you have. Similarly, we used Needle Python SDK to interact with the API, but you can use the API directly as well. We hope you enjoyed this tutorial and that you will find it useful in your projects.
If you have any questions or need help, feel free to reach out to us in our Discord channel.